EC2를 이용하여 서비스의 크기를 조절하기 위해서는 충분한 시간이 필요했습니다. Auto Scaling 기능의 매력은 충분하나, 급변하는 트래픽이나 사용량에 대해서 민첩하게 대응하기는 어렵습니다. 아무래도 OS부터 부팅되고 서비스가 올라가려면 5분 정도의 시간이 필요한데 그때쯤에는 급격한 트래픽이 다시 돌아오기에 충분하죠.
컨테이너 이미지의 장점은 이러한 상황에서도 빠르게 대응하는 것이 가능하다는 점일 것입니다. 준비된 OS 레이어 위에서 서비스만 배포되면 되기 때문에 컨테이너가 배포되는 시간은 보통 2분 이내이고, 빠르면 정말 몇 초만에도 가능합니다. 그래서 ECS Fargate로 이전한 서비스에 직접 적용해보기로 합니다.
Auto Scaling을 적용하게 된 계기
자원 정보를 수집하는 서버들은 OpsNow의 고객이 늘어남에 따라서 함께 늘어나기 시작했습니다. 좀 더 빠르고 많은 정보를 수집하려다보니 수집해야 하는 대상은 계속 늘어났고, 이를 적당히 분배해서 정해진 시간에 수집을 하게 되었습니다. 자원마다 수집 시기가 달랐는데, 사용하는 자원의 양이 일정하지가 않기 때문에 특정 시간대에는 상당히 많은 자원 정보를 빠르게 수집해야 했고, 서버의 갯수는 이처럼 최대치에 맞춰서 결정되었습니다.
최대치를 기준으로 하지 않으면 수집 시간이 과도하게 늘어날 수 있었고, 자원 수집은 제한된 시간을 최대한 충족해야 했습니다. 그래서 EC2의 Auto Scaling을 적용하기에는 무리가 있었지만, Fargate에서는 가능할 것 같아서 적용해보기로 합니다.
Auto Scaling을 적용하기 위해서는 크게 두 가지가 필요합니다.
- 어떤 메트릭을 기준으로 할 것인가
- 어떤 기준으로 서버를 증가, 감소, 또는 갯수를 고정할 것인가
자원 수집은 큐를 통해서 이루어지므로 큐에 쌓인 메시지 갯수를 이용하기로 합니다. 콘솔에서도 작업은 가능하지만, 이미 이전 글들을 통해서 Terraform으로 서비스가 구축되었기 때문에 해당 작업도 Terraform을 이용하도록 합니다.
Auto Scaling 적용하기
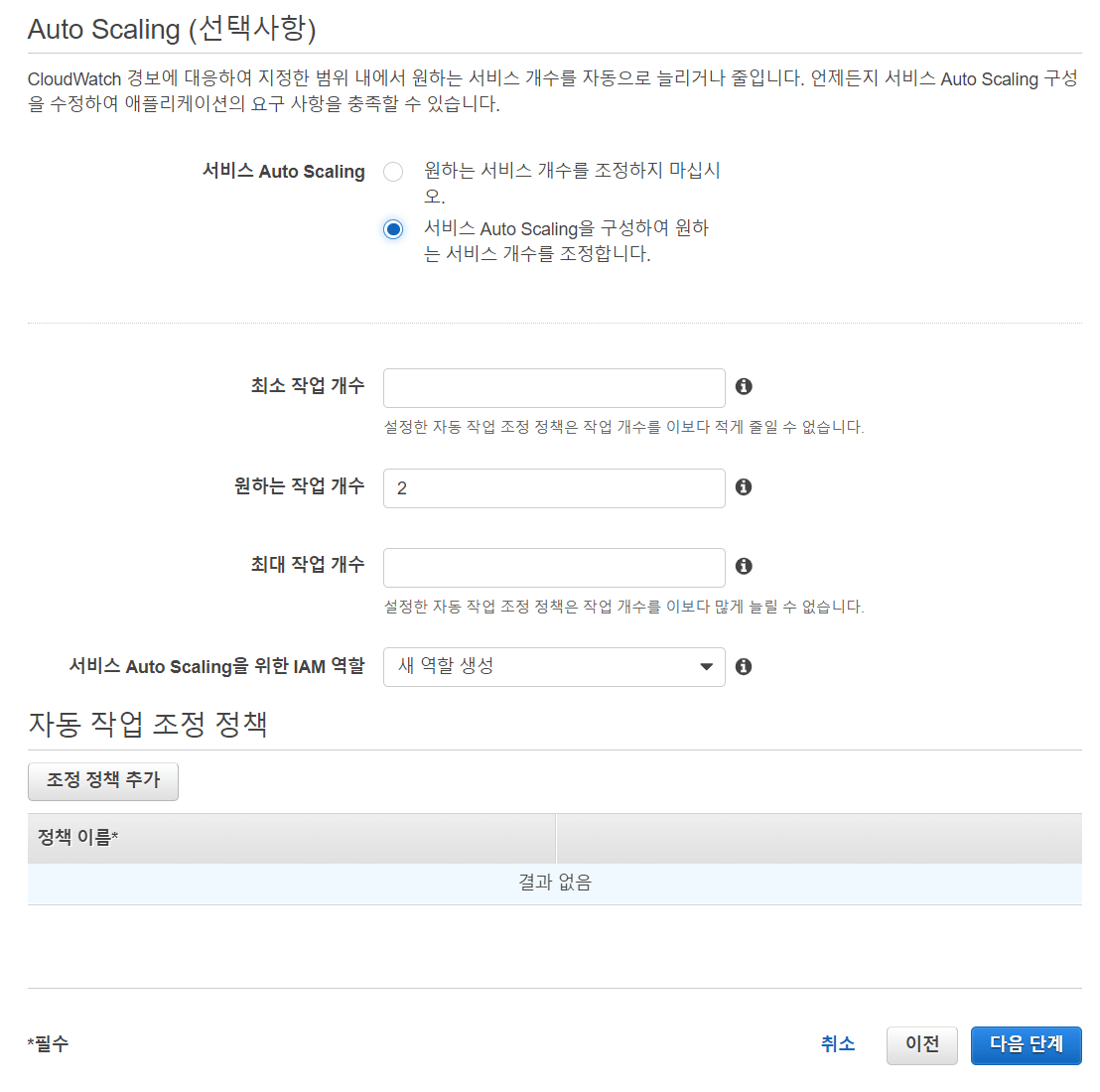
ECS 서비스에 Auto Scaling을 적용하려면 먼저 원하는 메트릭의 정보를 파악해야 합니다. 그리고 이러한 메트릭을 기반으로 CloudWatch 알람을 설정합니다. 알람이 경보 상태로 트리거가 되면서 Auto Scaling이 동작하는 구조입니다.
resource "aws_cloudwatch_metric_alarm" "ecs_service" {
alarm_name = "${var.name_ecs_service}-AUTO-SCALING"
alarm_actions = [ aws_appautoscaling_policy.ecs_policy.arn ]evaluation_periods = “1”
metric_name = “MessageCount”
namespace = “AWS/AmazonMQ”
period = “60”
statistic = “Maximum”
threshold = 0
insufficient_data_actions = []
“Broker” = “<my-broker>”
}
}
Code language: JavaScript (javascript)
저는 항상 알람을 기준으로 작업 갯수가 조절되기를 원하기 때문에, threshold를 0으로 잡아서 항상 경보가 울리도록 설정을 합니다. 1회성으로 작업 갯수를 조절하는 것이 아니라, 매 순간 메시지 갯수를 확인하고 그에 맞는 작업 갯수를 유지하는 방법을 사용하려는 것입니다.
resource "aws_appautoscaling_target" "ecs_target" {
max_capacity = 35
min_capacity = var.service_count
resource_id = "service/${var.cluster_name}/${var.name_ecs_service}"
scalable_dimension = "ecs:service:DesiredCount"
service_namespace = "ecs"
}name = “${var.name_ecs_service}-AUTO-SCALING”
policy_type = “StepScaling”
resource_id = “service/${var.cluster_name}/${var.name_ecs_service}”
scalable_dimension = “ecs:service:DesiredCount”
service_namespace = “ecs”
adjustment_type = “ExactCapacity”
cooldown = 0
metric_aggregation_type = “Maximum”
metric_interval_lower_bound = 0
metric_interval_upper_bound = 70000
scaling_adjustment = var.service_count
}
step_adjustment {
metric_interval_lower_bound = 70000
metric_interval_upper_bound = 150000
scaling_adjustment = 15
}
step_adjustment {
metric_interval_lower_bound = 150000
metric_interval_upper_bound = 300000
scaling_adjustment = 25
}
step_adjustment {
metric_interval_lower_bound = 300000
scaling_adjustment = 35
}
}
}
Code language: JavaScript (javascript)
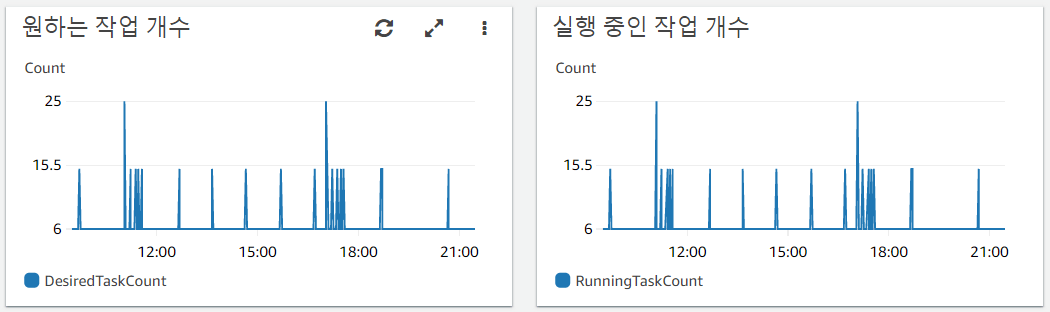
데이터 수집부와 처리부 모두에 다음과 같은 Scaling 정책을 생성합니다. 초기 작업 갯수에서 시작하여, 메시지 갯수에 따라 요구 작업 갯수를 ExactCapacity 방식으로 늘려나가는 것입니다. 이는 매 1분마다 작업을 변동할 수 있어서 반응이 매우 빠릅니다.
제가 하는 것처럼 Step Scaling 정책을 ExactCapacity로 적용하는게 아니라 다른 방식을 이용한다면 Step에 도달할 경우에 작업을 원하는 만큼 한 번만 늘리거나 줄이는 방식으로도 동작 가능합니다. 이럴 경우에는 cooldown을 설정해서 일정 시간만큼은 작업 갯수를 유지하도록 하는 것이 좋습니다.
이렇게 정책을 생성한 다음에 인프라 배포를 진행하면 곧바로 Auto Scaling이 적용됩니다.
Fargate Spot 적용하기
방금, EC2 17대가 하던 작업을 ECS 작업 6개 + Auto Scaling으로 꽤 많은 비용을 절감한 것 같습니다. 기왕 작업한 것, Fargate Spot을 적용해보기로 합니다.
resource "aws_ecs_service" "new" {
name = local.name_ecs_service
cluster = data.aws_ecs_cluster.default.id
desired_count = var.service_count
force_new_deployment = truebase = var.service_count
capacity_provider = “FARGATE”
weight = 0
}
capacity_provider_strategy {
base = 0
capacity_provider = “FARGATE_SPOT”
weight = 1
}
}
Code language: PHP (php)
기존의 launch_type을 삭제하고 capacity_provider_strategy를 새로이 추가합니다. 원하는 초기 갯수만큼은 FARGATE를 이용하고, 그 이후에 생성되는 작업에 대해서는 0:1의 비율, 모든 작업을 FARGATE_SPOT으로 생성합니다. 그러면 조금이라도 더 비용을 절감할 수 있을 것입니다.
운영계에만 적용하기
막상 Auto Scaling 기능을 구현하고 나니까 모든 스테이지에도 적용해야하는 문제가 발생했습니다. IaC의 형상 관리가 이럴때는 조금 답답합니다. 그래서 지금까지 작업한 위의 모든 코드를 Auto Scaling 모듈로 만들고, 해당 모듈을 운영 환경에서만 추가하도록 코드를 변경합니다.
module "auto_scaling" {
source = "./auto-scaling"
count = lower(var.stage) == "prd" ? 1 : 0cluster_name = var.cluster_name
name_ecs_service = local.name_ecs_service
aws_ecs_service.new
] }
Code language: JavaScript (javascript)
좋습니다. 이제 stage가 prd인 경우에만 해당 모듈을 1개 생성하여 배포하게 됩니다.
만약에 다른 인프라 코드에서 Auto Scaling 모듈 내의 리소스를 참조해야 한다면 count 함수에 의해서 참조 함수가 List 형태로 생성됩니다. 그러면 List의 Element를 참고하도록 변경해줘야 하지만, 다행히도 Auto Scaling 모듈은 모듈 내부 참조만 존재하기 때문에 다른 소스의 변경 없이도 손쉽게 모듈화가 가능하였습니다.
ECS의 Auto Scaling을 이용하여 5분 이내에 빠르게 변동하는 트래픽에 대응할 수 있는 인프라 구성을 적용하였습니다. 물론, 기존보다 리소스 변동 시간이 추가되어서 데이터 수집이 즉각적이지 않지만, 그에 따른 Trade-off로 상당한 비용도 절감할 수 있었던 것은 큰 이득입니다. 정말 미션 크리티컬한 성능이 필요한 것이 아니라면 위 글처럼 Auto Scaling의 이점을 꼭 누려보시기 바랍니다.