AWS에서는 특이하게도 매일 수집되는 빌링 데이터가 과거 데이터의 정합성을 보장하지 않습니다. 그래서 항상 한 달치 빌링 데이터 전체를 제공합니다. 매일 수집되는 데이터가 다르다는 가정 하에, OpsNow에서도 데이터를 누적하여 업데이트 하는 것이 아니라, 매번 수집된 데이터를 별도로 저장하고 있습니다.
수집된 OpsNow의 빌링 데이터는 EMR을 이용한 스파크 클러스터를 거쳐서 S3에 저장됩니다. 단순히 저장만 해놓게 되면 데이터를 분석/이용하기가 어렵기 때문에, 데이터에 접근하기 편리하도록 모든 데이터에 대해서 테이블을 생성하고 있습니다. 처음 수집된 데이터와 이후 처리된 데이터도 테이블을 분리 생성하여 CUR로 수집된 데이터 형태 그대로 분석하는 것이 가능합니다.
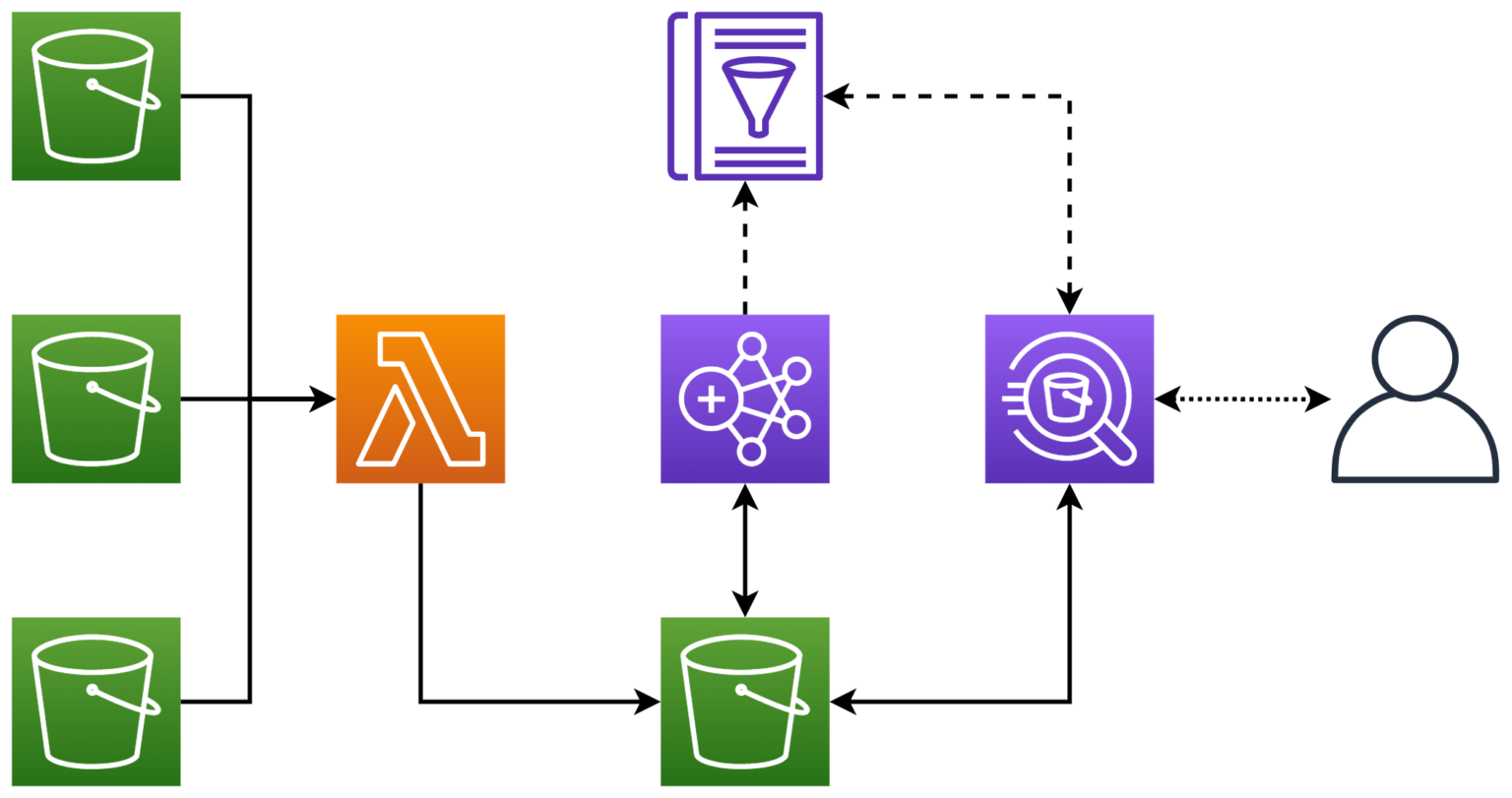
이렇게 수집된 데이터는 S3에, 테이블 메타데이터는 Glue Data Catalog, 그리고 쿼리 엔진은 Athena로 각각의 서비스가 완전히 분리되어 있습니다. 그러면 권한 관리는 어떻게 해야 할까요?
Athena 권한 관리
Athena를 정상적으로 이용하기 위해서는 결국 각각의 서비스에 대한 모든 권한을 부여받아야만 가능합니다. 총 4가지의 권한이 요구됩니다.
- 데이터가 저장된 S3에 대한 권한
- 메타 데이터가 저장된 Glue Data Catalog에 대한 권한
- 데이터를 쿼리하기 위한 Athena에 대한 권한
- 쿼리 결과를 저장하기 위한 S3에 대한 추가 권한
먼저 S3 데이터 엑세스 권한입니다. Athena를 이용하면서 데이터를 읽고 쓸 수 있는 권한이 필요합니다. 그에 따른 최소한의 권한만 담았습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucketMultipartUploads",
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::<bucket>"
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": "arn:aws:s3:::<bucket>/*"
}
]
}
Code language: JSON / JSON with Comments (json)
그 다음은 Glue Data Catalog 권한입니다. 메타 데이터에 접근 가능한 데이터베이스와 테이블을 일일히 지정해줄 수 있습니다. 특히, 보안을 위해서 특정 아이피 대역에서만 접근 가능하도록 하였습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:SearchTables",
"glue:GetDatabase",
"glue:GetCatalogImportStatus",
"glue:GetPartition",
"glue:GetTableVersion",
"glue:GetTables",
"glue:GetTableVersions",
"glue:GetPartitions",
"glue:GetDatabases",
"glue:GetTable"
],
"Resource": [
"arn:aws:glue:ap-northeast-2:<account>:database/<database>",
"arn:aws:glue:ap-northeast-2:<account>:table/<database>/*",
"arn:aws:glue:ap-northeast-2:<account>:catalog"
],
"Condition": {
"IpAddress": {
"aws:SourceIp": "<source_ip>/32"
}
}
},
{
"Effect": "Allow",
"Action": "glue:GetDataCatalogEncryptionSettings",
"Resource": "*",
"Condition": {
"IpAddress": {
"aws:SourceIp": "<source_ip>/32"
}
}
}
]
}
Code language: JSON / JSON with Comments (json)
이제 Athena 권한입니다. 이미 데이터와 메타 데이터에 대한 권한이 위에서 전부 정의가 되었기 때문에, Athena에서는 쿼리 실행과 관련한 권한만 추가하면 됩니다. 마찬가지로 아이피 제한을 걸 수 있습니다. 그리고 추가적으로, 비용 관리를 위해서 특정 작업 그룹 (Workgroup)에 대한 제한 조건이 걸려 있습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"athena:GetTableMetadata",
"athena:StartQueryExecution",
"athena:GetQueryResultsStream",
"athena:GetQueryResults",
"athena:GetDatabase",
"athena:GetDataCatalog",
"athena:GetNamedQuery",
"athena:ListTagsForResource",
"athena:ListQueryExecutions",
"athena:ListNamedQueries",
"athena:GetWorkGroup",
"athena:ListDatabases",
"athena:StopQueryExecution",
"athena:GetQueryExecution",
"athena:BatchGetNamedQuery",
"athena:ListTableMetadata",
"athena:BatchGetQueryExecution"
],
"Resource": [
"arn:aws:athena:ap-northeast-2:<account>:workgroup/<workgroup>",
"arn:aws:athena:ap-northeast-2:<account>:datacatalog/AwsDataCatalog"
],
"Condition": {
"IpAddress": {
"aws:SourceIp": "<source_ip>/32"
}
}
},
{
"Effect": "Allow",
"Action": [
"athena:ListDataCatalogs",
"athena:ListWorkGroups"
],
"Resource": "*",
"Condition": {
"IpAddress": {
"aws:SourceIp": "<source_ip>/32"
}
}
}
]
}
Code language: JSON / JSON with Comments (json)
마지막으로 Athena의 쿼리 결과를 저장하게 될 S3에 대한 권한입니다. 이 부분은 위에서 S3 권한 획득을 위한 IAM 정책과 동일하게 설정할 수 있습니다. 버킷만 새로 생성해서 추가하면 됩니다.
이렇게 위와 같은 권한을 사용자별 혹은 사용자 그룹별로 별도 생성해야 합니다. 굉장히 번거로운 일이 아닐 수 없습니다. 그래서 이런 불편함을 해소하고 중앙 집중식으로 권한 관리를 제공하기 위한 서비스가 바로 AWS Lake Formation 입니다! AWS에서 S3를 이용한 데이터 레이크를 손쉽게 구축하고 간편하게 사전 정의된 ETL 작업을 생성할 수 있으며, 데이터 저장소와 카탈로그, 테이블 그리고 심지어 컬럼 레벨까지의 권한 관리를 단 한 곳에서 제공하는 서비스라고 합니다.
본래 이번 글에서 함께 소개해보고자 했었는데, 위의 IAM 기반 권한 관리와 Lake Formation의 권한 관리가 충돌하면서 일종의 Migration 절차가 필요한 것으로 보입니다. 저희도 얼른 적용해보고 정리가 완료되면 Lake Formation에 대해서 자세한 내용을 공유하도록 하겠습니다.
Athena에 클라이언트 연결
Athena에서는 클라이언트 연결을 위해서 별도의 JDBC 드라이버를 제공하고 있습니다. (바로가기) 물론, 일반 사용자가 손쉽게 사용하기 위해서는 클라이언트 툴이 필요한데, 사실 Athena를 지원하는 클라이언트 툴이 그렇게 많지가 않습니다.
그럼에도 불구하고 Athena를 지원하는 DBeaver Community Edition을 OpsNow 팀에서는 주로 활용하고 있습니다. 일반적으로 많이 사용하는 데이터베이스 외에도 다양한 데이터베이스 연결을 제공해주고 있어서 커넥션을 통합 관리하기가 용이합니다.
DBeaver 툴을 설치 완료하였으면, 좌측 상단의 + 기호가 포함된 플러그 모양을 눌러줍니다. 그러면 아래와 같이 다양한 데이터베이스를 선택할 수 있습니다.

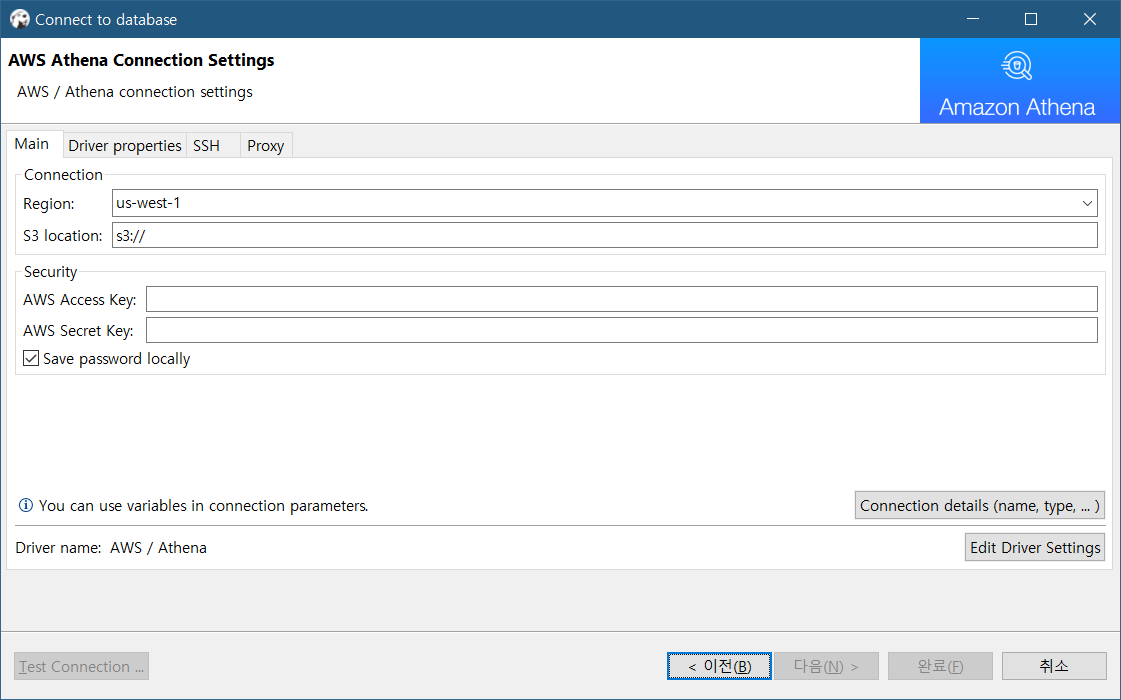
다음으로 넘어가면 리전과 쿼리 결과를 저장할 S3, 그리고 로그인을 위한 Access Key를 요구합니다. 앞서 권한 관리를 통해서 적절한 권한을 IAM 사용자에게 부여하고, 사용자의 프로그래밍 액세스 방식을 위한 Access Key를 발급해서 사용하시면 됩니다.
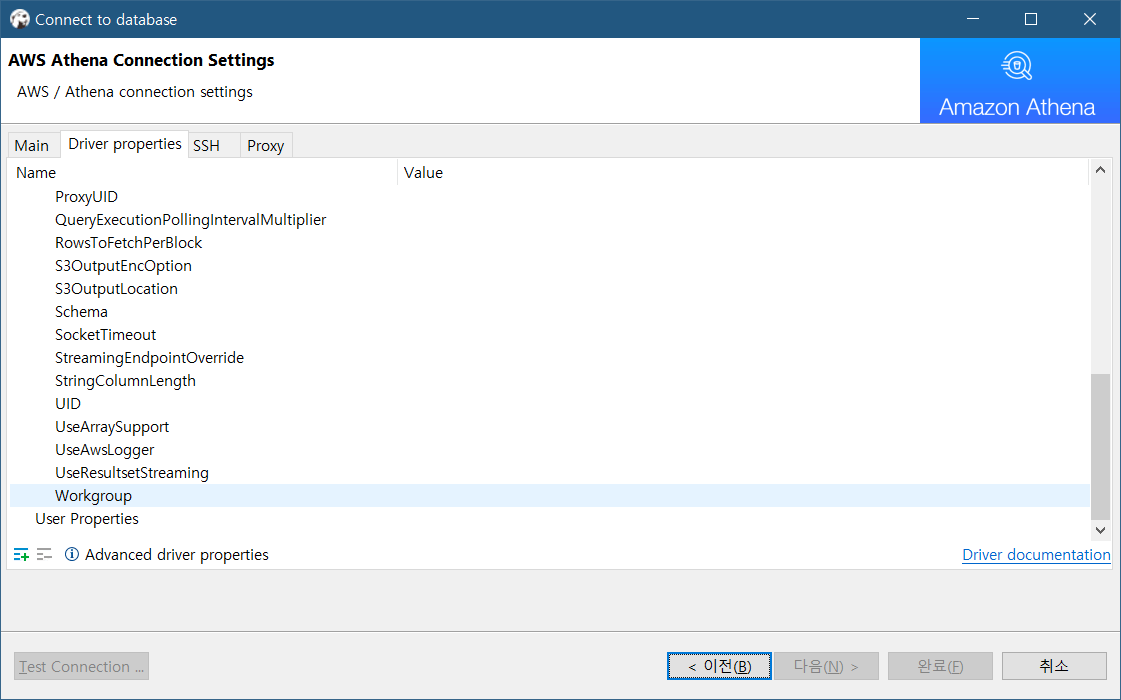
Athena의 작업 그룹을 별도로 이용하고자 하는 경우에는 아래와 같이 드라이버 설정에서 직접 입력해서 사용할 수 있습니다. 별도 입력하지 않으면 default 그룹으로 설정되는데, IAM 사용자가 특정 작업 그룹에만 권한이 있으면 쿼리가 되지 않습니다. 작업 그룹별로 비용을 추적할 수 있어서 비용 관리를 목적으로 구분하시면 좋습니다.
모든 설정이 완료되었으면 쿼리를 실행함으로써 정상적으로 설정이 완료되었는지 확인합니다. 권한에 문제가 있으면 오류 메시지를 통해서 어떤 권한이 문제가 있는지 확인하실 수 있습니다.