세상에 너무나 많은 데이터가 생성됨으로 인해서 빅데이터 시대가 열렸고, 이 시대에 스파크 (Spark)와 하둡 (Hadoop)은 각각 분산 처리와 분산 파일 시스템의 대명사 격으로 자리잡았습니다. 이들이 있었기에 대용량의 데이터를 수평적인 확장을 통해서 다룰 수 있게 되었습니다.
OpsNow에서도 내부적으로 AWS 등의 빌링 데이터를 일괄 처리하기 위해서 스파크를 사용하고 있었습니다. 하지만 스파크를 전문적으로 다룰 수 있는 개발자가 없어서 많은 사람들이 새롭게 공부해가면서 스파크 클러스터를 구축하고 운영해왔습니다. 스파크에서 가장 흔히 사용되는 스칼라 (Scala) 언어조차도 보통의 개발자에게는 생소했기 때문에 초기에는 자바 (Java) 소스에서 컨버팅해서 개발했던 것 같습니다.
개발 당시에는 별 다른 문제가 없었지만, OpsNow를 사용하는 고객이 늘어남에 따라서 빌링 데이터의 크기도 빠르게 늘어나기 시작했습니다. 그러나, 데이터가 증가하는 속도에 비해서 데이터가 처리되는 속도는 너무나 느렸고 그 속도는 클러스터의 노드를 늘렸음에도 빨라지지 않았습니다. 분명히 수평 확장이 가능하다고 알고 있는데, 대체 무슨 일이 있었던 걸까요?
해결의 실마리
저는 정확히 어느 부분이 문제인지를 명확하게 파악하기 위해서 다양한 시도를 하였습니다.
가장 먼저 시도한 것은 충분한 리소스를 제공하는 것이었습니다. 기존 EC2의 스파크 클러스터를 EMR로 전환하고 노드 크기를 대폭 늘렸음에도 시간은 거의 동일하였습니다. 노드 크기가 문제가 아니었던 것입니다. 드라이버 (Driver), 익스큐터 (Executor) 설정을 변경해봐도 아주 작은 시간의 차이만 발생하였고 결과적으로는 문제를 해결할 수 없었습니다.
그 다음으로 시도한 것이 로직 최적화 입니다. 당시 소스에서는 사용자 정의 함수를 다수 사용하였고, 일부 로직은 RDD (Resilient Distributed Dataset)를 그대로 사용하면서 드라이버 노드의 부하를 일으키고 있었습니다. 이러한 부하를 분산시키기 위해서 드라이버 노드로 데이터가 몰리지 않도록 로직을 개선하였는데, 이렇게 해서 대략 10~15% 정도의 시간 단축을 이룰 수 있었으나 원하는 만큼의 속도 개선은 이루어지지 못했습니다.
마지막으로 시도한 작업은 내부 작업의 병렬화 입니다. 스파크 자체가 병렬 처리를 하는데, 작업의 병렬화가 무슨 뜻이냐고요? 조금 더 정확하게 얘기하자면, 스파크는 분산 처리 플랫폼으로 하나의 작업을 여러 대의 노드를 통해서 작업을 나누어 진행할 수 있습니다. 흔히 이것을 병렬 처리라고 부르기도 합니다. 하지만, 작업은 결국 한 번에 하나씩 실행되고 있었던 것입니다!
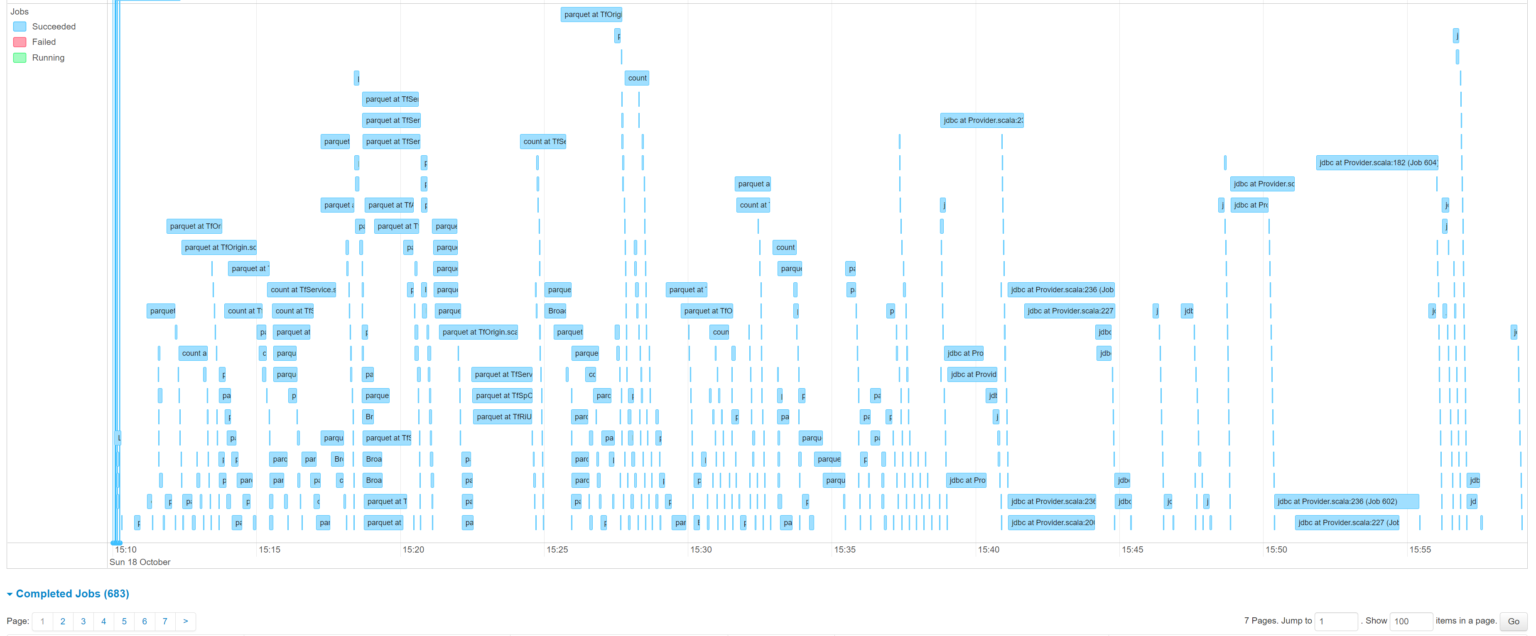
작업의 병렬 처리를 구현하고 나서 스파크 UI에서 작업이 실행되는 상태를 확인하고 나니 허탈해졌습니다. 이제서야 원하는 수준까지 시간이 단축되었습니다. 기존 대비 80% 이상의 단축이 있었습니다!
스파크 작업의 병렬 처리
방법은 크게 어렵지 않습니다. 스파크 내부적으로는 작업 스케줄러를 사용하고 있는데, 기본적으로 FIFO (First In, First Out) 모드를 사용하고 있습니다. 이것을 FAIR 모드로 바꿔주고 작업을 병렬로 제공하기만 하면 됩니다.
스칼라 프로젝트의 경우에는 가장 먼저 Resources 폴더에 fair.xml이라는 파일을 생성하고 아래 내용을 추가합니다.
<allocations>
<pool name="fair">
<schedulingMode>FAIR</schedulingMode>
<weight>10</weight>
<minShare>0</minShare>
</pool>
</allocations>
Code language: HTML, XML (xml)
그 후에 SparkSession을 생성하면 아래와 같은 옵션을 제공하여 스케줄러를 선택합니다. 스케줄러 선택은 최초로 상위에서 스파크의 세션을 생성하면서 한 번만 지정하면 됩니다.
val sparkMaster = SparkSession.builder.appName("AWS Billing System").getOrCreate()
sparkMaster.sparkContext.setLocalProperty("spark.scheduler.mode", "FAIR")
sparkMaster.sparkContext.setLocalProperty("spark.scheduler.allocation.file", getClass.getResource("/fair.xml").getPath)
sparkMaster.sparkContext.setLocalProperty("spark.scheduler.pool", "fair")
Code language: Scala (scala)
이제 작업 목록을 병렬화 하여 foreach 등으로 실행하고 그 안에서 새로운 스파크 세션을 생성하여 각각의 작업을 처리하면 됩니다. 새로운 세션을 생성하지 않으면 같은 스파크 세션을 공유하게 됩니다. 그러면 메모리를 함께 사용하여 데이터가 뒤섞이므로 반드시 새롭게 생성해야 합니다.
val jobList = getList(jobs).par
jobList foreach { job =>
val spark = sparkMaster.newSession
// do whatever
}
Code language: Scala (scala)
단 몇 줄의 코드만으로 스파크 작업의 병렬 처리가 구현되었습니다.
EMR 스텝의 동시 처리
아예 코드가 필요 없는 방법도 존재합니다. EMR에서 스파크 작업을 수행하기 위해서는 스텝 (Steps)으로 추가해야 합니다. 이 과정에서 동시성 (Concurrency) 옵션을 체크하면 Yarn의 FairScheduler 기능을 통해서 스파크 작업을 동시에 수행하는 것이 가능합니다. 앞선 과정이 스파크 내부에서 스케줄러를 통한 병렬 처리였다면, 이번에는 Yarn을 통해서 병렬 처리를 진행하는 것입니다.
콘솔의 경우에는 아래와 같이 설정 단계에서 옵션을 손쉽게 켤 수 있습니다. CLI 환경에서도 한 줄만 추가해주면 됩니다.
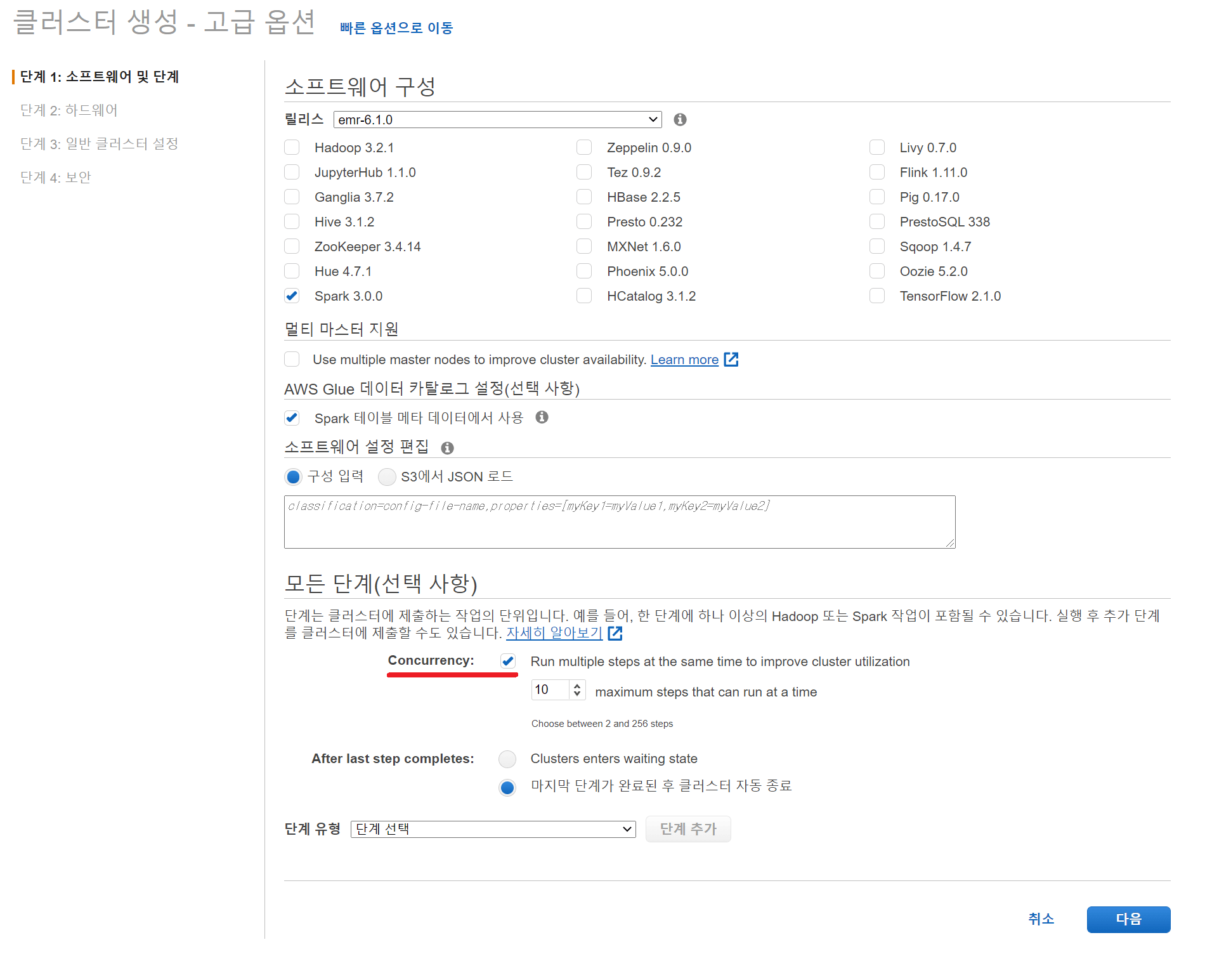
그러면, 스파크의 스케줄러와는 다르게 스텝으로 제공된 각각의 스파크 작업을 동시에 처리하게 됩니다.
얼핏 보기에는 둘이 어떤 차이인지 잘 모를 수 있습니다. 그러면 하나의 예를 들어 생각해볼 수 있습니다. 내가 만약에 스파크 작업의 병렬 처리가 끝난 후에 모든 작업에 의존하는 후처리가 필요하다면 어떻게 해야 할까요? 전자의 경우에는 스파크 내부적으로 작업의 뒤로 후처리를 추가하기만 하면 손쉽게 해결 가능하지만 후자의 경우에는 별도의 작업 관리 툴이 없으면 모든 스텝이 끝났는지 확인하면서 대기하다가 작업이 완료되어야만 후처리가 가능하게 됩니다.
각각의 작업이 독립적이라면 EMR 스텝의 동시 처리를 이용하는 것이 유리하고, 각각의 작업이 추후 연결되어야 한다면 약간의 수고를 더해서 스파크 작업의 병렬 처리를 진행하는 것이 유리할 것입니다. 이렇게, 작업의 목적에 알맞은 병렬 처리 방식을 선택해서 리소스를 남기지 않고 최대한 효율적으로 사용하여 비용과 시간을 절감할 수 있습니다.