이번에는 구체적으로 배치를 어떻게 개선했는지 정리해보겠습니다. 크게 불필요한 작업을 없애거나 순서를 변경하는 것으로 프로세스를 개선한 건과 작업 병렬화를 통해 처리 시간을 줄인 개선 건이 있습니다.
작업 프로세스 개선
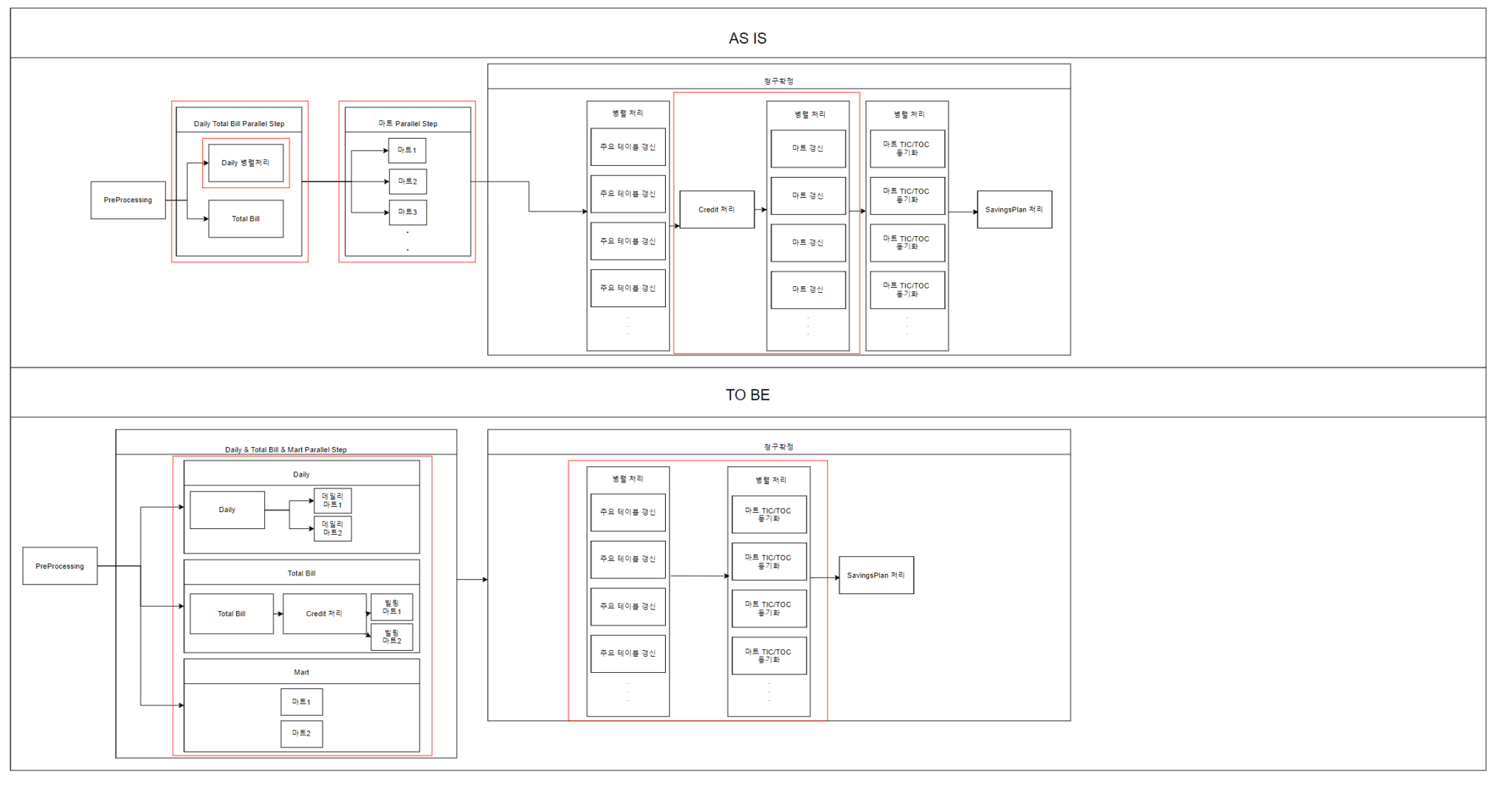
여러 Case가 있었지만, 대표적 2가지만 적어보고자 합니다.
- Case 1 : 기존에는 단순히 Mart라는 이유로 같이 묶어서 병렬로 처리하였는데, 그 마트들을 데이터의 선,후행 관계를 분석하여 데일리 마트, 빌링 마트, 일반 마트 3종류로 구분하였습니다. 그 후에 관련 선행 작업 있으면 그 작업이 끝난 뒤 바로 처리하고, 관련 없는 마트는 별도로 작업하도록 변경하였습니다. 이 중 제일 오래 소요되는 일반 마트 작업이 다른 작업들과 병렬로 수행되어 배치 시간을 많이 줄일 수 있었습니다.
- Case 2 : 한달에 한 번 Credit 작업을 하게 되는데, 이 때 마트 데이터도 같이 변경됩니다. 하지만 이 작업을 마트 작업 전에 수행 한다면 추가로 중복된 마트 데이터 변경을 할 필요가 없어집니다. 단순히 순서를 변경했을 뿐인데도 중복된 마트 작업을 없애는 효과로 시간을 많이 줄일 수 있었습니다.
작업 병렬화를 통한 개선
스프링 배치 병렬화에 사용한 것은 크게 2종류입니다. Parallel Steps과 Partitioning이 바로 그것입니다.
- Parallel Steps은 말 그대로 작업을 병렬로 동시에 실행하는 것입니다. 단일 작업의 성능 향상은 없지만, 병렬로 돌기에 여러 작업 중 제일 오래걸리는 시간 만큼만 소요됩니다.(병렬 작업이 성능에 영향을 주지 않을 때) 이 때 주의할 점은 병렬로 돌릴 작업 간에는 같은 테이블을 지우거나 업데이트 하는 것이 없어야 합니다. 간단한 설정만으로 병렬 작업으로 돌릴 수 있어서 좋지만, 너무 한번에 많이 돌리게 되면 메모리나 CPU가 버티지 못할 수도 있습니다.
- Partitioning은 하나의 작업을 본인이 원하는 단위로 쪼개어서 돌릴 수 있게 해줍니다. 현재 100개의 회사의 데이터를 처리하고 싶으면, Partitioner를 이용해서 10개의 파티션에 10개의 회사의 데이터를 각각 나눠줍니다. 그러면 10개의 파티션이 동시에 10개의 회사의 데이터를 처리하게 됩니다. 병렬로 실행할 때 각 파티션의 성능만 보장된다면 매우 드라마틱한 효과를 기대할 수 있습니다. 물론 Parallel Steps와 마찬가지로 사용중인 CPU와 메모리가 버틸 수 있을 정도로만 구현해야 합니다.
스프링 배치의 장점
직접 사용해보니 스프링 배치의 가장 큰 장점 중 하나는 작업들의 관리와 상태 관리가 쉽다는 점입니다. 각 작업들을 어떻게 병렬 혹은 순차적으로 혹은 조건 부로 진행할지 쉽게 설정이 가능하고, 메타 데이터를 통해 각 작업의 상태를 쉽게 확인할 수 있었습니다. 또한 제일 범용적으로 쓰이는 스프링 프레임워크 기반이기에 쉽게 접근이 가능한 것도 큰 장점입니다.
어려웠던 점
직접 구현해보니 병렬 작업에서 제일 어려웠던 점은 실제 운영계와 비슷한 환경에서의 테스트를 통한 안정화였습니다. 개발계에서는 잘 동작했던 것들이 데이터가 훨씬 많은 운영계에서는 동작하지 않았던 적도 있었습니다. 그래서 최대한 운영계와 비슷한 환경을 갖춘 검증계를 만들어 테스트하기도 했습니다.