오늘은 머신 러닝의 이런저런 것에 대해서 공유해 드리려고 합니다. 머신 러닝은 인공 지능의 한 영역으로 컴퓨터가 스스로 학습하는 것을 말합니다. 머신 러닝을 번역하면 기계 학습으로 번역되니, 번역된 내용 그대로입니다.
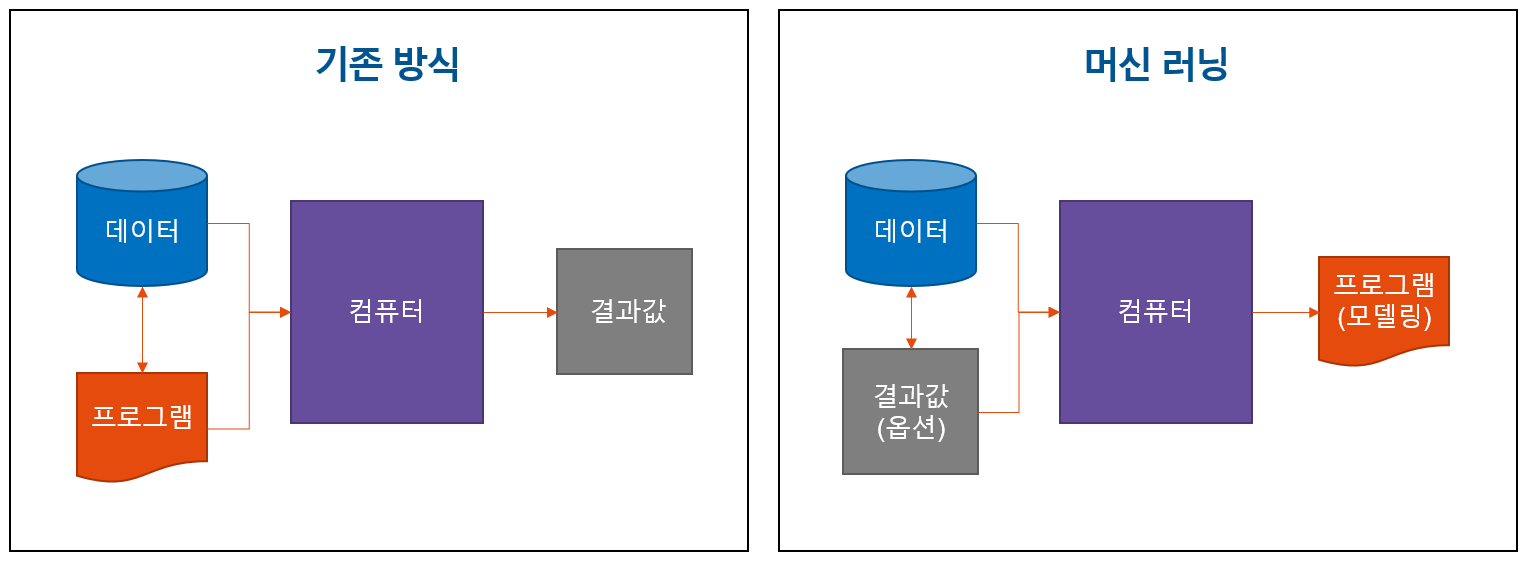
위 그림에서처럼, 기존에는 프로그램과 데이터를 통해 컴퓨터가 결과값을 내는 방식이라면, 머신 러닝에서는 데이터와 결과값을 가지고 컴퓨터가 처리를 한 후 프로그램(모델링)을 생성해 내는 것입니다. 즉, 예전에는 사람이 생각하여 특정 프로그램을 만들고 그 프로그램을 컴퓨터가 처리해서 결과를 보여 주었다면, 머신 러닝은 데이터를 기반으로 컴퓨터가 분석하여 특정 패턴을 가진 모델링(프로그램)을 하게 되는 것입니다. 물론 컴퓨터가 데이터를 분석하여 모델링을 한다고 하더라도 컴퓨터가 사람처럼 할 수는 없습니다. 그렇기에 이미 정의되어 있는 여러가지 방식의 알고리즘을 사용하게 되는 것이죠. |
머신 러닝의 종류머신 러닝은 다음 4가지로 구분됩니다.
지도 학습(Supervised Learning) 지도 학습이란 사람이 입력 값과 출력 값을 제공하여 학습을 시키는 것을 의미합니다. 즉, 문제와 정답이 있는 데이터를 기계가 학습하여 나중에 이런 문제가 주어지면 정답을 예측해 주는 것입니다. 예를 들어, 강아지의 사진(입력 값)과 출력 값(강아지 여부)이 있는 데이터를 주면 기계는 강아지 사진과 그 사진이 강아지라는 정보를 기반으로 학습을 하게 됩니다. 그리고 추후에 어떤 사진을 받았을 때 그 사진이 강아지인지의 여부를 출력해 줄 수 있는 것입니다. 비지도 학습(Unsupervised Learning) 비지도 학습이란 지도 학습과는 다르게 사람이 문제와 정답을 제공해 주지 않습니다. 그냥 기계에게 데이터를 제공해 주면 기계가 직접 특정 패턴이나 형태를 찾아내게 됩니다. 예를 들어, 많은 강아지와 고양이 사진을 기계에게 주면 기계는 그 사진들을 범주화를 시켜 유사한 특징의 사진들을 그룹화해 주는 것입니다. 지도 학습에서는 어떤 사진이 강아지인지를 기계가 알아 낼 수 있지만, 비지도 학습에서는 강아지의 여부는 알 수 없고, 유사한 특성의 사진들을 그룹화만 하는 것이죠. 준지도 학습(Semi-Supervised Learning) 준지도 학습은 위 두 가지(지도/비지도) 학습을 혼합해서 사용하는 것입니다. 강화 학습(Reinforcement Learning) 자신의 행동에 대한 보상이나 페널티를 통해서 가장 적절한 모델링을 진행하는 것입니다. 기계가 직접 1. 현재 환경 및 상황을 탐색하고, 2. 자신의 판단에 따른 최적의 정책 선택 후 실행하고, 3. 실행 액션의 결과를 통해 보상 또는 페널티를 적용하고, 4. 필요한 경우 정책을 수정하고, 계속해서 1 ~ 5 단계를 반복하면서 최적의 정책을 만들어 가는 것입니다. 예를 들어 장난감 자동차가 스스로 올바른 트랙을 찾아서 돈다고 할 때, 자동차가 자신이 설정한 정책으로 전진하다가 벽에 부딪히면, 거기에 벽이 있으니 거기서는 왼쪽으로 조금 핸들을 꺾어야 한다고 정책을 수정하고, 다시 처음부터 가다가 거기서 또 부딪히면 다시 조금 더 많이 왼쪽으로 핸들을 꺾어야 한다고 정책을 수정하고, 이렇게 계속 반복해 나가면서 트랙을 부딪히지 않고 완주할 수 있도록 학습해 나가게 되는 것입니다. |
머신 러닝에 사용되는 알고리즘지도 학습
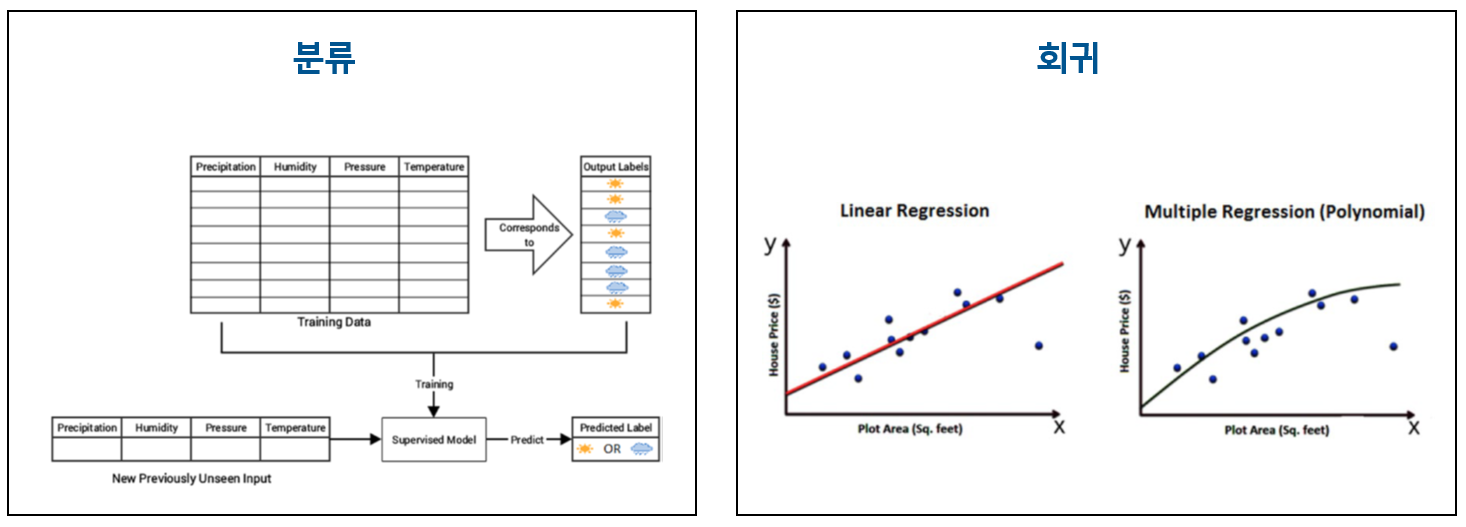
이진 분류(Binary Classification): 입력값에 따라 두 가지의 결과로 분류하는 것입니다. 이는 주로 참/거짓을 분류하는 데 사용합니다. 예를 들어 사진을 입력했을 때 강아지인지 아닌지의 여부를 확인해 주는 것입니다. 다중 분류(Multi-class Classification): 입력값에 따라 이진 분류보다 더 많은 세 가지 이상의 결과로 분류하는 것입니다. 예를 들어 입력된 숫자 이미지를 1 ~ 9로 분류할 수 있는 것이죠. 회귀(Regression): 둘 이상의 변수 간의 관계를 보고 예측할 수 있는 것입니다. 비지도 학습
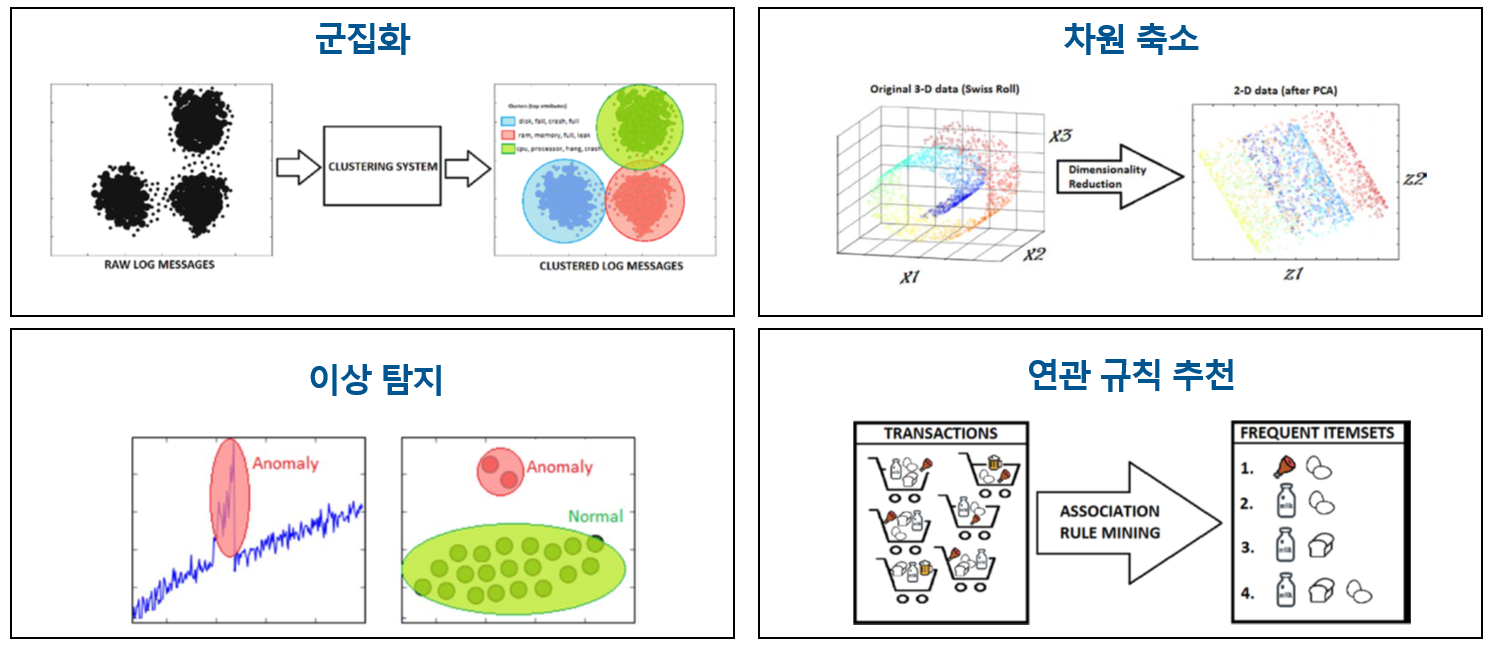
군집화(Clustering): 입력된 데이터를 분류해 주는 방법입니다. 데이터들 사이에서 거리 상 가까운 것들끼리 각 군집으로 분류해 주는 것이죠. 이상 탐지(Abnormal Detection): 데이터들 중에서 예상과는 심하게 다른 패턴을 보이는 데이터를 찾는 것입니다. 차원 축소(Dimensionality Reduction): 특정 목적에 따라서 데이터의 양을 줄이는 방법입니다. 이를 통해 데이터의 양이 줄어들면 복잡도가 줄어들기에 이를 활용합니다. 연관 규칙 추천(Association Rule Mining): 특정 데이터에서 의미 있는 규칙을 발견하기 위해서 사용됩니다. 예를 들어 그림과 같이 우유를 사는 사람이 계란이나 빵을 같이 사용하는 빈도가 어떻게 되는지에 대한 규칙을 찾는 것이죠. |
| 오늘은 머신 러닝에 대해서 간략히 공유해 드렸습니다. 저도 몇 년간 머신 러닝에 대해서 공부를 해 봤지만, 이런 기술들이 미래에 정확히 어떤 영향을 주게 될지는 잘 모르겠습니다.
하지만, 확실한 것은 이로 인해 세상은 많이 변할 것이란 것입니다. 그렇기에 이런 변화에 적응할 수 있도록 기업도 개인도 준비를 해 두어야 하지 않을까 하는 생각이 듭니다. 찰스 다윈의 다음 명언처럼 살아 남기 위해서는 변화에 잘 적응해야 하니까 말이죠. It is not the strongest of the species that survives, nor the most intelligent that survives. It is the one that is most adaptable to change. 가장 강한 종이나 가장 똑똑한 종이 살아 남는 것은 아니다. 변화에 가장 잘 적응하는 종이 살아 남게 되는 것이다. |
| 클라우드나 SaaS와 관련하여 다른 궁금한 점이 있으시면 언제든지 저희에게 문의해 주세요.
저희에게는 클라우드에 대한 다양한 정보와 경험, 그리고 도구가 있습니다.
|