얼마 전에 갑자기 비용이 소폭 상승하여 그 원인을 찾고자 다양한 메트릭을 확인하게 되었습니다. 이번 글에서는 그 과정을 기록 차원에서 남겨보고자 합니다.
이상 비용
AWS 조직 계정에서 비용을 살펴보던 도중에 최근 비용이 증가하는 것을 발견하였습니다. 비용 절감 차원에서 다양한 시도를 하고 있는데 비용이 증가할 리는 없으니 무언가 잘못되었다는 신호가 분명합니다. 여러 차원으로 살펴본 결과, 두 가지 비용이 평소 대비 크게 상승한 것을 발견할 수 있었습니다.
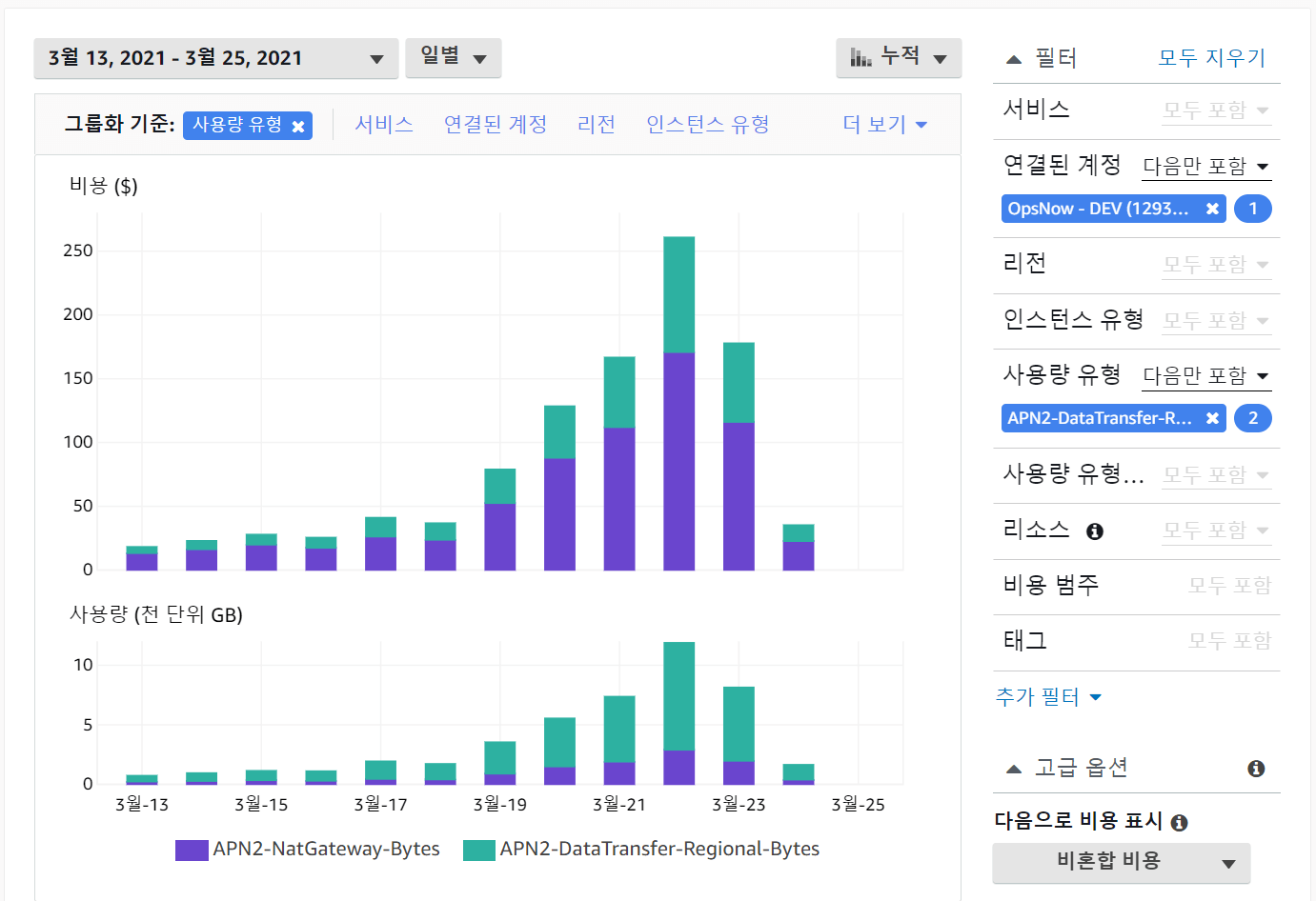
사용량과 비용이 증가한 항목은 다음 두 가지 입니다.
- APN2-NatGateway-Bytes : NAT가 외부와 주고 받는 데이터의 양입니다.
- APN2-DataTransfer-Regional-Bytes : NAT가 내부에서 처리하는 데이터 양입니다.
갑자기 VPC 내부에서 대량의 데이터가 가용 영역을 뛰어넘어서 발생하였고, 그 중에 일부는 다시 외부로 전송되면서 두 비용이 늘어나게 된 것입니다.
이상 트래픽
실제로 NAT 게이트웨이의 메트릭을 살펴보면 데이터 처리량이 증가한 것을 확인할 수 있습니다. 개발 인프라에는 총 5대의 NAT가 존재하는데, 그 중에 3대가 이상 트래픽이 발생한 것도 확인하였습니다.
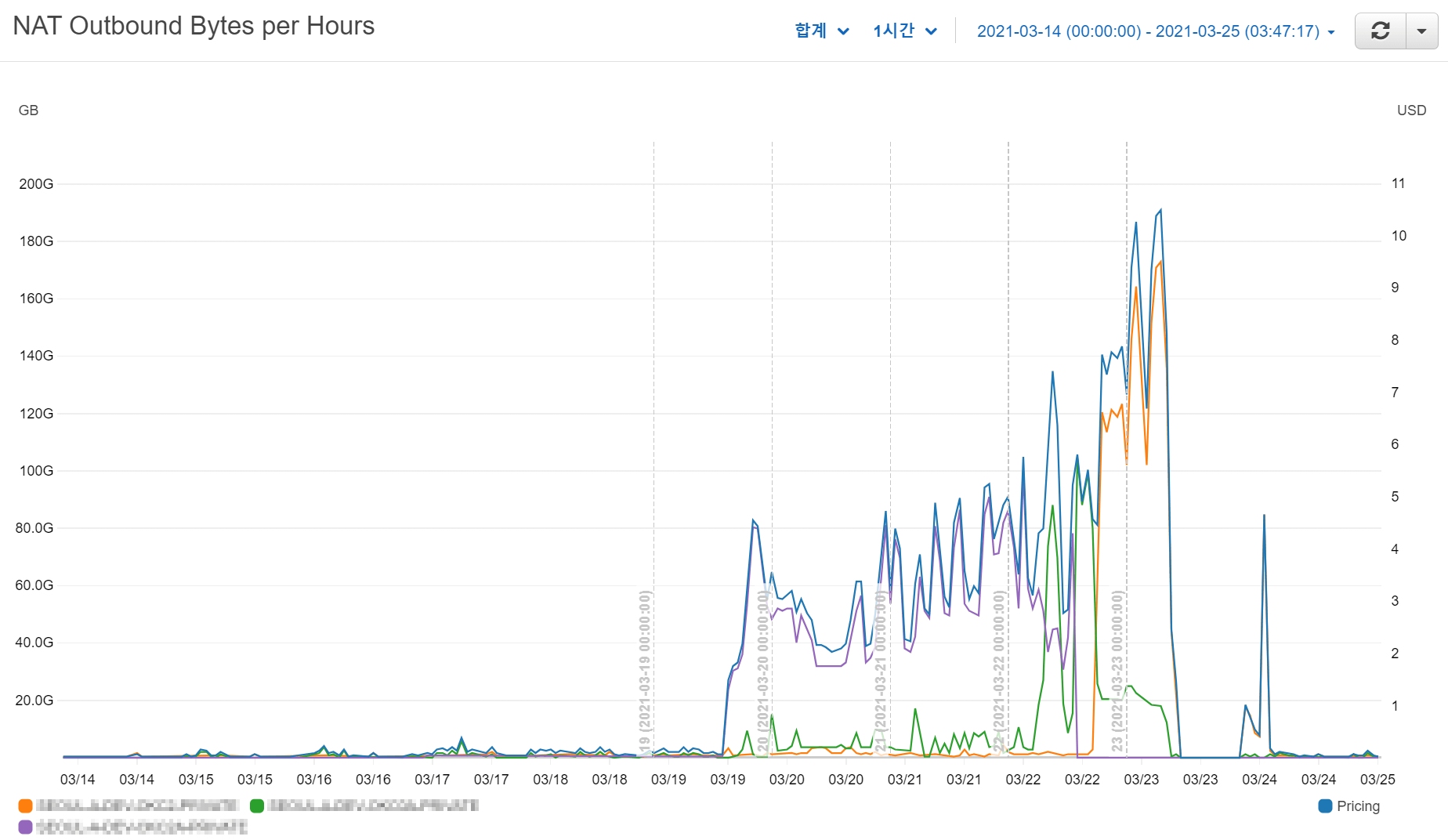
보시는 바와 같이 3대의 NAT에서 여러 날에 걸쳐서 번갈아가며 이상 트래픽이 발생하였고, 그에 따라서 NAT의 데이터 처리량에 따른 비용이 발생하였습니다. 시간당 집계 그래프에서 금액이 초반에는 3~4 USD였다가 나중에는 10 USD까지 증가하는 것을 확인할 수 있습니다.
그러면 도대체 어떤 데이터가 왜 외부로 나간 것일까요?
로그 분석
우선 NAT 3대의 내부 아이피를 확인하고 VPC 플로우 로그를 통해서 어디로 데이터를 전송한 것인지 파악해보기로 합니다. 다음과 같은 Logs Insights 쿼리를 사용합니다. 아이피의 마지막 자리는 블라인드 처리하였습니다.
stats sum(bytes) / 1024 / 1024 / 1024 as bytesTransferred by srcAddr, dstAddr
| filter srcAddr in ["10.251.43.*", "10.251.53.*", "10.252.55.*"]
| sort bytesTransferred desc
| limit 10
Code language: JavaScript (javascript)
조회 구간을 앞서 메트릭으로 살펴본 것과 동일하게 설정하고 조회를 하면 다음과 같이 결과를 확인할 수 있습니다.

상위 10개만 조회해봤는데 데이터를 가장 많이 전송한 주요 아이피 몇 개가 등장합니다. 사설 아이피를 제외한 모든 곳이 AWS 서비스 아이피 대역임을 확인하였습니다. 그리고 인프라 담당자를 통해서 아이피가 가리키는 AWS 서비스 엔드포인트는 Elastisearch 였음을 확인할 수 있었습니다. (이 부분은 운이 좋았습니다.)
이상 로그
Elastisearch 서비스에서 역시 메트릭을 찾아봅니다. 사용 가능한 Documents 숫자에 대한 메트릭이 무언가 이상합니다.
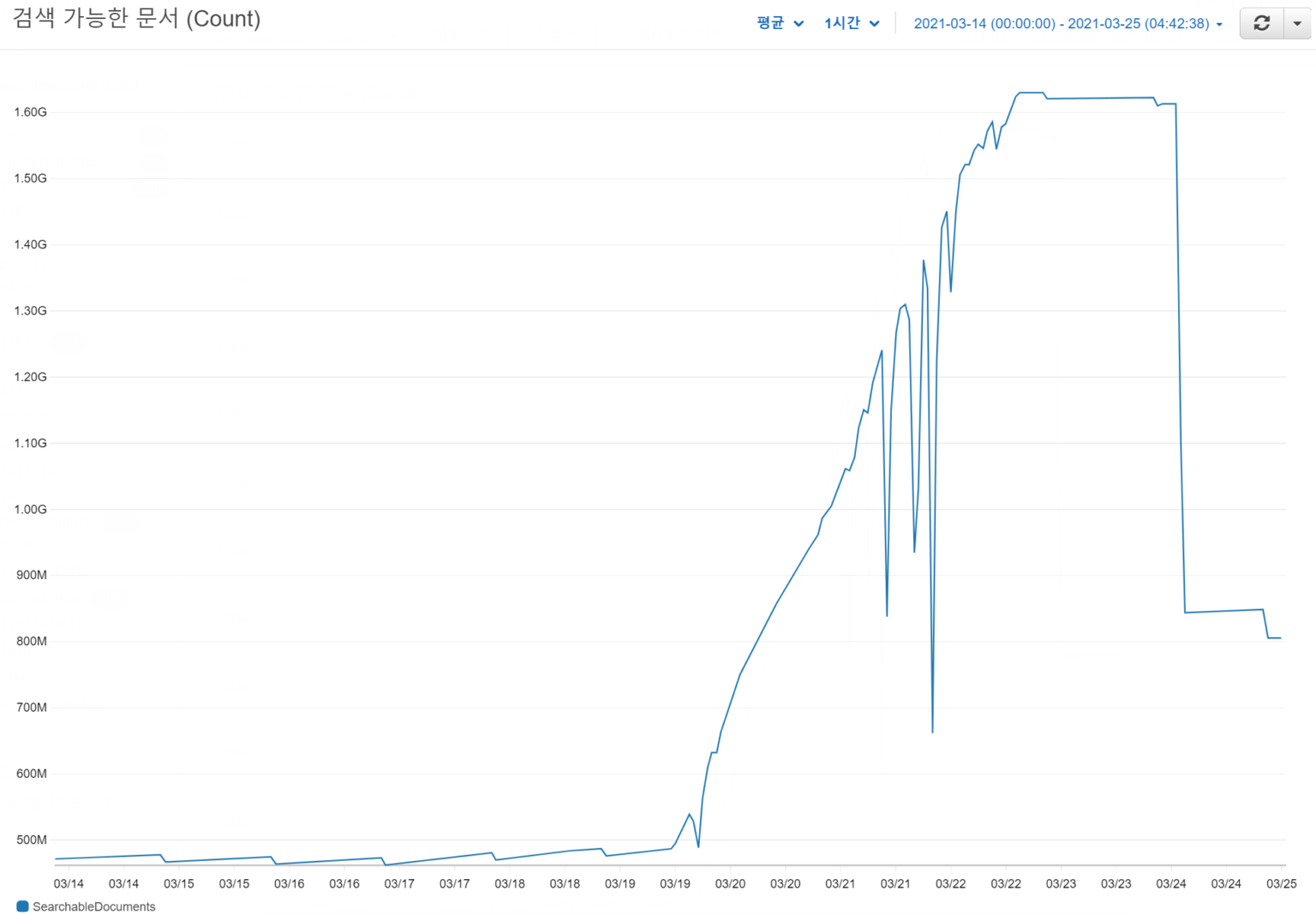
해당 Elastisearch 서비스는 k8s의 로그 적재를 위해서 사용하는 것인데, 로그의 양이 기존 대비 3배가 넘게 대량으로 증가한 것을 확인할 수 있었습니다. 또한 Elastisearch의 저장 공간도 급작스럽게 감소하였음을 확인하였습니다. k8s에서 모종의 사유로 발생한 대량의 로그가 적절히 처리되지 못하고 계속 Elastisearch로 전송되면서 분당 2GB 내외의 로그가 쌓이는 일이 수일간 지속되었던 것입니다.
인프라 담당자에게 노티를 하고 이슈를 마무리하는 동안에 발생한 비용은 약 750 USD 정도입니다. 이런 이상 현상을 제대로 파악하지 못했다면 하루에 약 200 USD가 계속 발생했을 것을 생각하니까 등골이 아찔합니다. 😪